


It's well known at this point that building production-grade LLM products is hard. Reliability is critical for any product to succeed, but when your product is underpinned by a series of probabilistic functions, ensuring reliability is far from straightforward.
At Dosu, we are continuously iterating on our product. For every change we make, we need to understand its impact on end users. Evaluation driven development (EDD) allows us to ship with confidence. Over the last few months, LangSmith has allowed us to scale EDD by enabling us to easily monitor and search Dosu's activity.
What is Dosu?
If you've spent any time on the LangChain GitHub repository, you may have already met Dosu, an AI teammate that helps develop, maintain, and support software projects.
Dosu was born out of my time as an open source software maintainer, a rewarding, but notoriously time-consuming role. As my OSS project grew in popularity, I found myself spending far more time playing support instead of developing new features.
For maintainers, this responsibility frequently causes burnout and has driven some to declare issue bankruptcy, a process that involves simply closing all open issues and PRs. The OSS community also suffers from this situation, as people often wait days, weeks, or even months for a maintainer to respond to their issues.
This phenomenon isn't exclusive to open source. Within the industry, up to 85% of developers' time is spent on non-coding tasks, like answering ad-hoc questions, triaging issues, and processing overhead.
Dosu takes these tasks off developers' plates, so they can do what they love: stay in flow, code, and ship great features. At the same time, Dosu is a resource to the OSS community, giving community members immediate feedback whenever they run into an unforeseen issue or have novel questions that only code can answer.
Early Days
Dosu launched in late June, 2023. Back then, our volume was low enough for us to inspect every single response. Each day, armed with just grep and print statements, we meticulously combed through logs to identify areas for improvement.
The work was painstaking, but it was important for designing and developing Dosu's architecture. It helped our team deeply understand how people were trying to use Dosu, which types of requests it excelled at, and ones where it fell short.
Once we knew what we needed to improve, the question was how to improve it. Unlike traditional code updates, changing LLM logic is not straightforward. It's difficult to know how a small change might affect performance as a whole. Many times we saw that a slight tweak to a prompt led to better results in one domain but caused regression in another.
We needed a way to measure the impact of our changes. For every change, we wanted to make sure that we were:
- Maintaining performance in areas where we were doing well
- Improving performance in areas where we were struggling
It was during these early days that we turned to evaluation driven development to benchmark our progress.
Evaluation Driven Development
Evaluation driven development (EDD), like test driven development, gives us an end goal to develop against. The evaluations — or "evals" — are our baseline for understanding updates and new functionality. EDD helps us understand the impact of any change we make to Dosu's core logic, models, or prompts.
With EDD, we have a well-defined process for improving Dosu:
- Create a new behavior with a handful of initial evals
- Launch the new behavior to users
- Monitor results in production and identify failure modes
- Add examples for each failure mode to our offline evals
- Iterate on the updated evals to improve performance
- Relaunch & repeat
This development workflow worked well for us when Dosu started, but as our usage grew, it became difficult to keep up with Dosu's activity.
Keeping the Quality Bar High at Scale
Today, Dosu is installed on thousands of repositories and generates responses at all hours of the day. We've built dozens of submodules to intelligently handle different types of scenarios, and we're constantly iterating on our approach to problem solving as models and the research in the field evolve.
While the growth of Dosu was exciting, it came with challenges. Dosu's increased activity made it nearly impossible to monitor responses and identify failure modes in production, which is critical to our EDD workflow.
We decided it was time to upgrade our LLM monitoring stack. We looked for a tool that could not only help us monitor Dosu's activity, but that was flexible enough to fit into our existing workflow. Some of our criteria included:
- Prompts must live in Git — In the ethos of EDD, we treat prompts as code. Any changes to a prompt must be treated with the same standards as code changes.
- Code-level tracing — There is more to Dosu than a series of LLM requests. We wanted to track metadata between LLM requests within a single trace.
- Easy to export data — We had existing evaluation datasets and tooling that we wanted to keep.
- Customizable and extensible — The LLM space is rapidly evolving. There is no standard way of building LLM apps. We wanted control over what metadata is tracked and the ability to tailor the tool to meet our needs.
We explored the LLM monitoring and evaluation landscape, trying to find a product that satisfied our requirements. After a call with the LangChain team, one of our early partners, we were pleased to hear that LangSmith seemed to check all the boxes.
Implementing LangSmith via the SDK
What got us most excited about LangSmith wasn't its sleek UI or extensive feature set, but actually its SDK. The LangSmith SDK gave us the fine-grain controls and customizability we were looking for.
To try out LangSmith, we just had to add a @traceable decorator to a few of our LLM-related functions. It only took us minutes to instrument, and immediately upon pushing these changes to production we saw traces flooding into the LangSmith UI.

An unexpectedly awesome feature of the @traceable decorator is it can send the function and LLM call traces to LangSmith. This allows us to see the raw function inputs, rendered prompt templates, and LLM output all in a single trace in the LangSmith UI.
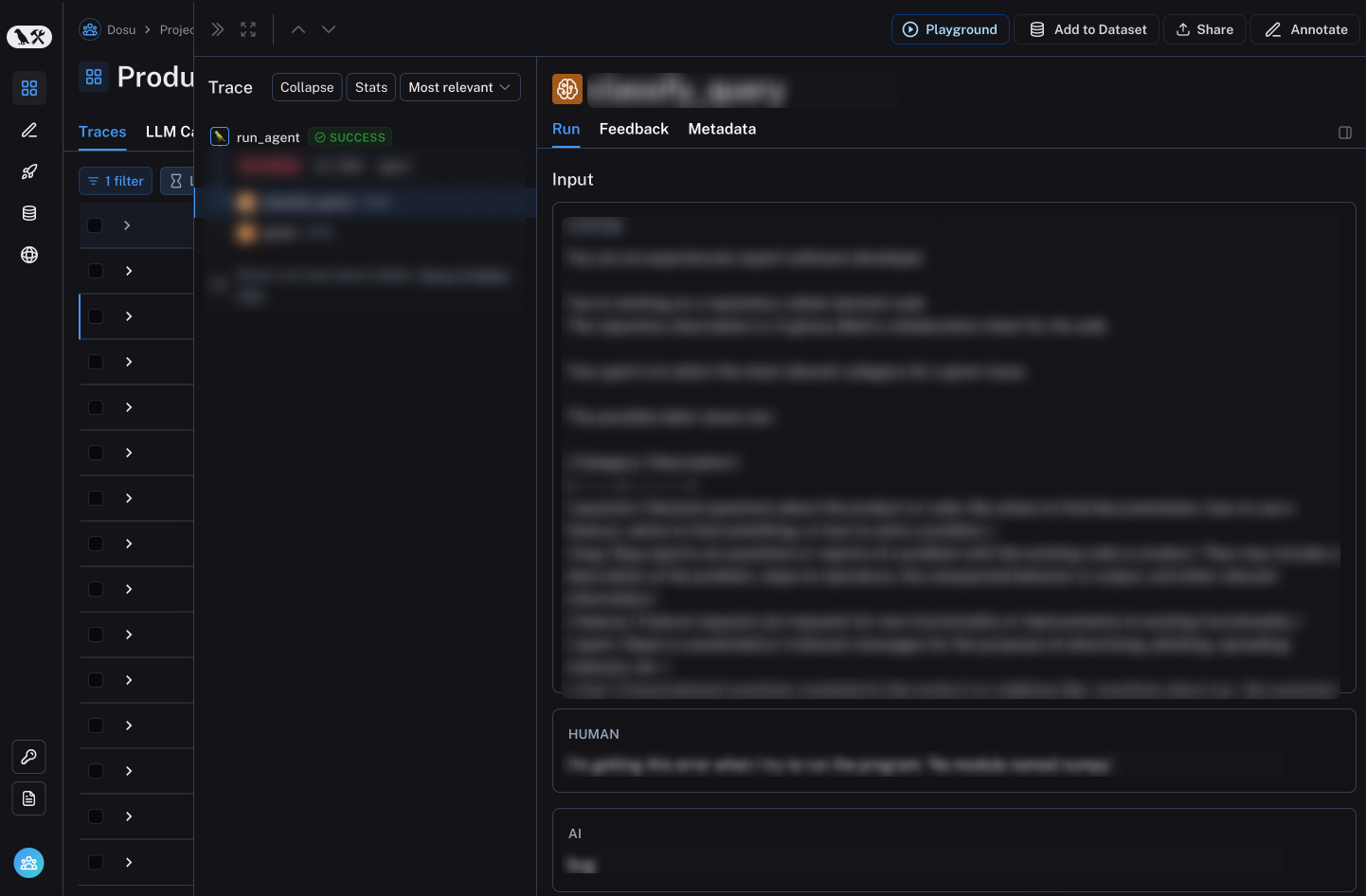
Out-of-the-box, LangSmith gave us visibility into all of Dosu's activity. The next step was to leverage LangSmith to identify failure modes and integrate it into our EDD workflow.
Finding Failures
Dosu receives a myriad of requests from users—everything from simple questions about a codebase, to error traces from upgrading to a new library version, to asking about the status of a feature. More possible inputs to Dosu means more possible failure modes.
When trying to identify failure modes, or requests that Dosu doesn't handle well, we have a variety of signals to look for like:
- Explicit Feedback: The classic thumbs up/down feedback popularized by ChatGPT
- User Sentiment: When users interact with Dosu on GitHub issues, their responses usually show whether or not Dosu was helpful
- Internal Errors: LLMs can fail for a number of reasons. Was the input or output too large? Did the generated response not match the desired schema?
- Response Time: At Dosu, we prioritize quality over speed; however, understanding why a response is slow matters.
LangSmith's advanced search functionality makes it easy to identify anomalous behaviors. We can perform searches using a range of criteria, including: explicit user feedback, recent error incidents, response time delays, or negative sentiment. LangSmith also allows us to attach additional metadata to each trace to further extend its search capabilities.
Already, we've identified a number of unforeseen failure modes. For example, we found a pattern of extremely slow responses when users would share thousands of lines of logs or the raw float values of an OpenAI embedding.
One of our team's favorite failures happened when Dosu was asked to label a pull request. Rather than labeling the pull request, Dosu decided it should tell the user about the concert it was excited to go to that night. Jury is still out on whether Dosu is a Swiftie.

Once we find a failure mode, the EDD workflow is the same as before:
- We search LangSmith for additional examples
- Add them to our eval datasets
- Iterate against the evals
- Push a new version of Dosu, and repeat
Automating Evaluation Dataset Collection
The future of evaluation driven development at Dosu is bright. Our team is customizing LangSmith even further to allow us to automatically build evaluation datasets from production traffic. We want it to be as simple as possible for engineers at Dosu to curate datasets based on conversation topics, user segments, request categories, and more.
There is a fun flywheel effect in Dosu's collaboration with LangChain. LangSmith helps us iterate faster to improve Dosu's performance. Improvements to Dosu directly translate to reducing the maintenance and support burden on the LangChain team, allowing them to spend more time shipping features for LangSmith, which in turn speeds up the development of Dosu. And so the process continues!